Time series ML | Wake-word detection with DSCNNs
Wake-word detection or key word spotting (KWS) is an excellent time series problem in Machine learning. To be functional, it must be fast, accurate, and robust in noisy environments. In most setups, this detection is done with lightweight models running directly on the device. However, Alexa is known for having a 2 stage approach where the on-device detector triggers and then a short snippet of audio is sent to the cloud for verification on a more powerful model. To avoid sending our voice data to the cloud we must find a reliable solution.
Why DSCNN instead of CNN?
Standard convolutional neural networks (CNNs) work well for keyword spotting but they are often heavier than necessary for edge devices. Depthwise seperable convolutional neural networks (DSCNNs) replace expensive convolutions with a two step factorization (depthwise + pointwise), dramatically reducing compute while keeping accuracy similar in many situations.
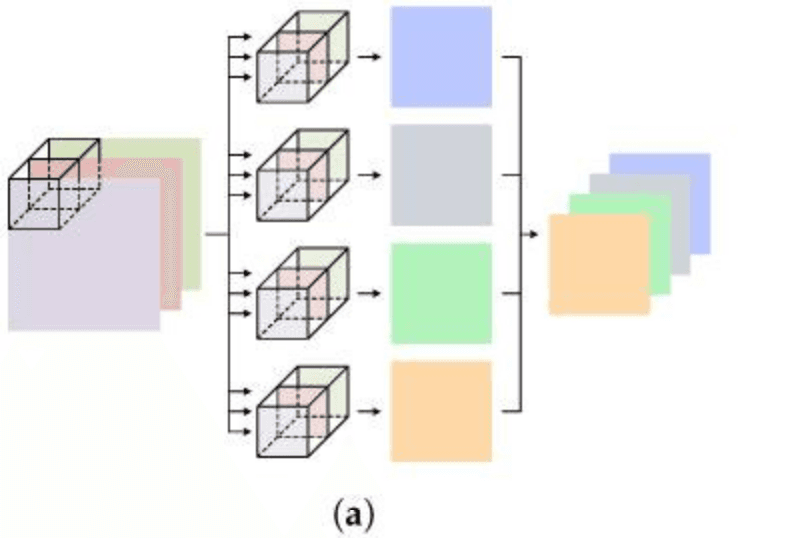
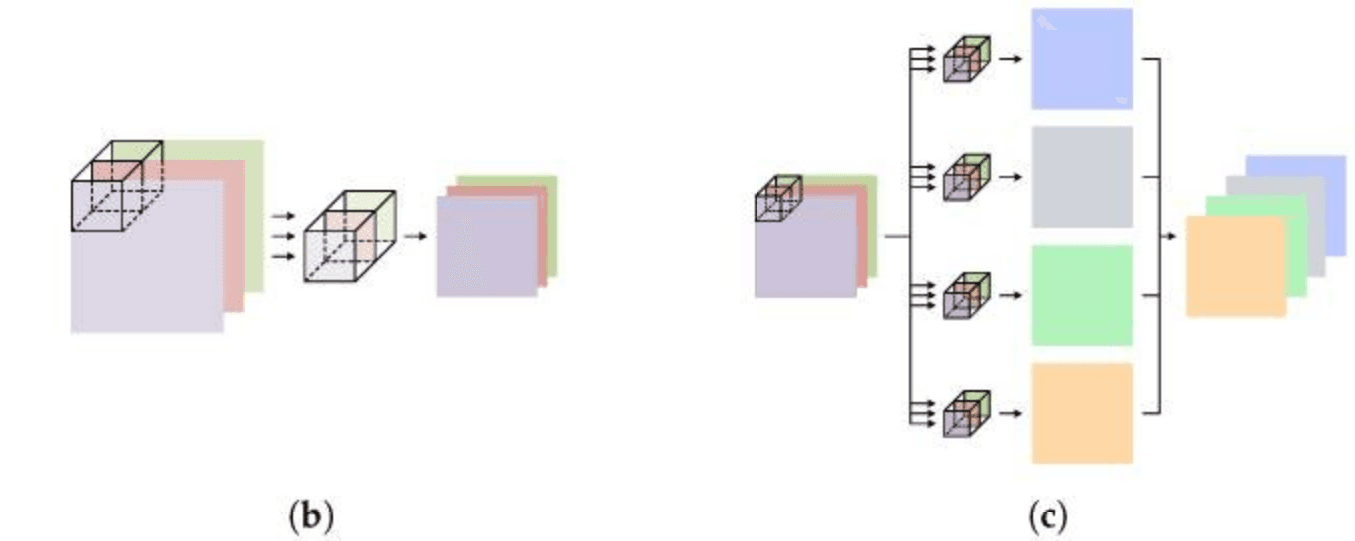
Input: Hin x Win x Cin
Kernel: Kh x Kw
Output channels: Cout
Output map: Hout x Wout
Standard convolution learns spatial filtering and channel mixing in one step. The multiply-accumulate operations (MACs) scales as:
MACsconv = Hout x Wout x Cout x (K² x Cin)
(and parameters scale as K² x Cin x Cout)
Depthwise-separable convolution splits this into:
1) Depthwise (one K x K filter per input channel): MACsdw = Hout x Wout x Cin x K²
2) Pointwise (1x1 channel mixing): MACspw = Hout x Wout x Cin x Cout
Total:
MACsDS = Hout x Wout x (Cin x K² + Cin x Cout)
Compared to standard conv, the DS-CNN cost ratio is approximately:
MACsDS / MACsconv ≈ 1/Cout + 1/K²
So with K = 3 (K² = 9) and depending on channel widths, DSCNNs are around 7-9x cheaper
Speech features (log-mel) and how the model “sees” audio
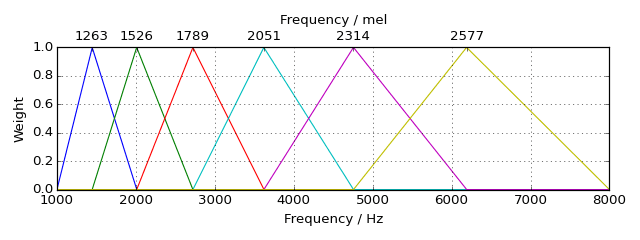
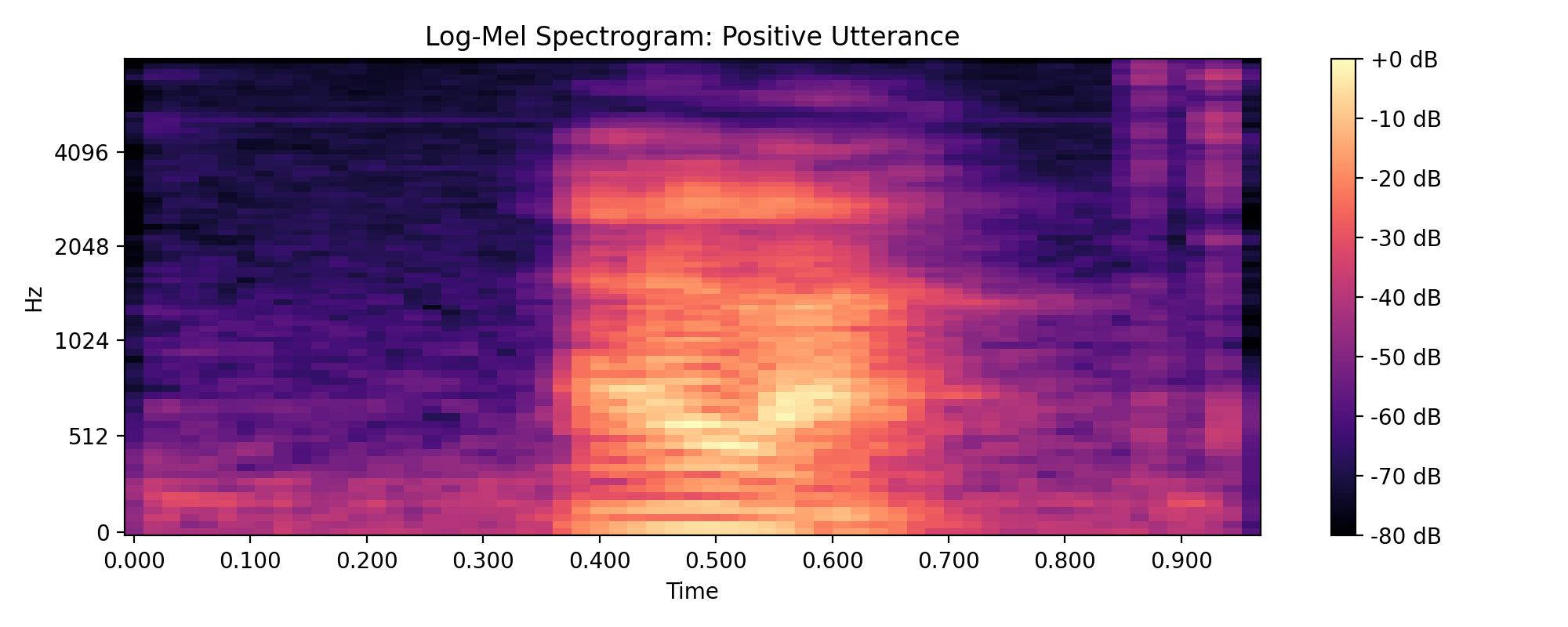
Raw waveforms are information dense but expensive to learn from, and are generally considered overkill for ML purposes. Instead we can compress this information into what is called a log-mel spectrogram which is a time-frequency representation with usually around 30-60 frequency bins. The frequencies are grouped using a mel scale which perceptually aligns with human hearing.
Feature pipeline
- 1) Window audio: We collect short 10-20ms frames of audio with an overlap
- 2) Short Time Fourier Transform (STFT): We convert each window into frequency bins each associated with a complex coefficient that represents the magnitude and phase of that frequency component in the window
- 3) Mel filterbank: We apply a set of overlapping triangular filters that are narrower at lower frequencies and wider at higher frequencies. We do this because human hearing is more sensitive to lower frequencies so granularity is more important there.
- 4) Log compression: We shrink the large dynamic range of the mel spectrogram by applying a logarithm. This prevents large magnitude frequency bins from overwhelming quiter (likely more important) details. This allows for easier learning and also better aligns with actual human perception of loudness which is logarithmic in nature