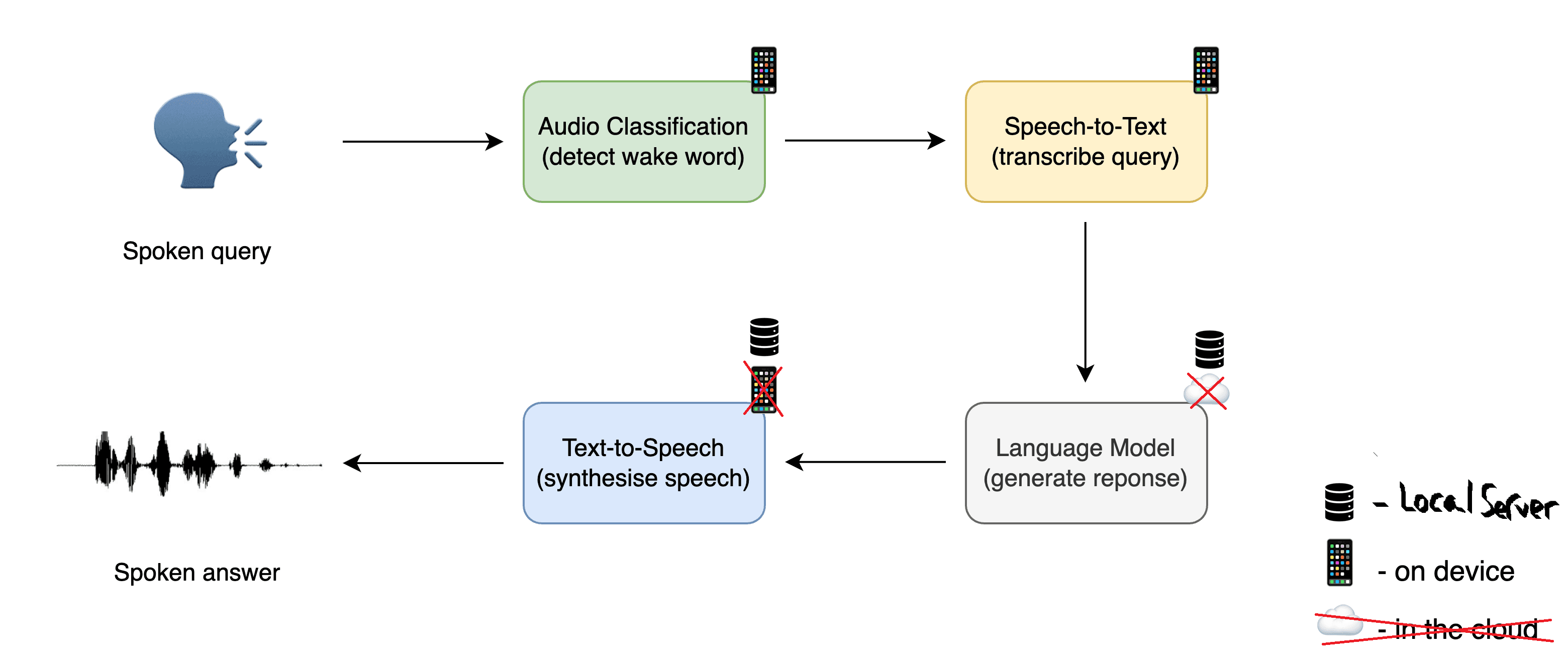
Voice Pipeline
Additional Components: Personalization + Turn-taking
Beyond WW -> STT -> LLM -> TTS, some additions such as Speaker Identification and Voice Activity Detection can enhance personalization and the conversational experience itself.
Speaker Identification Module
A self-learning classifier that estimates who is speaking and outputs a confidence score. When confidence is sufficiently high, Ella can qualify responses with personalized context.
- Speaker profiles as datasets: Each person corresponds to a growing bucket of labeled audio samples.
- Low confidence fallback: If the score falls below a threshold, the response is not personalized.
- Dataset Augmentation: With explicit consent, the new audio is stored as labeled training data.
- Periodic Model Updates: The model is updated periodically to improve accuracy as the dataset grows.
There is a clean separation between an “identity estimate” and “personalization permission”, so even a correct ID doesn’t automatically imply using sensitive context. We can create a policy protocol that weighs the confidence score against the sensitivity of the context and decides the appropriate level of personalization.

Voice Activity Detection (VAD)
After wake-word activation, Ella must then begin a very complex turn-by-turn process that is expected in human conversation. Sometimes the user is talking, sometimes Ella is talking, each can accidentally or purposefully interrupt each other. VAD is an essential piece to minimise frustration or misunderstandings during an interaction.
VAD runs continuously to detect speech versus non-speech. Its outputs inform the endpointing and barge-in logic to keep turn-taking and interruption handling natural.
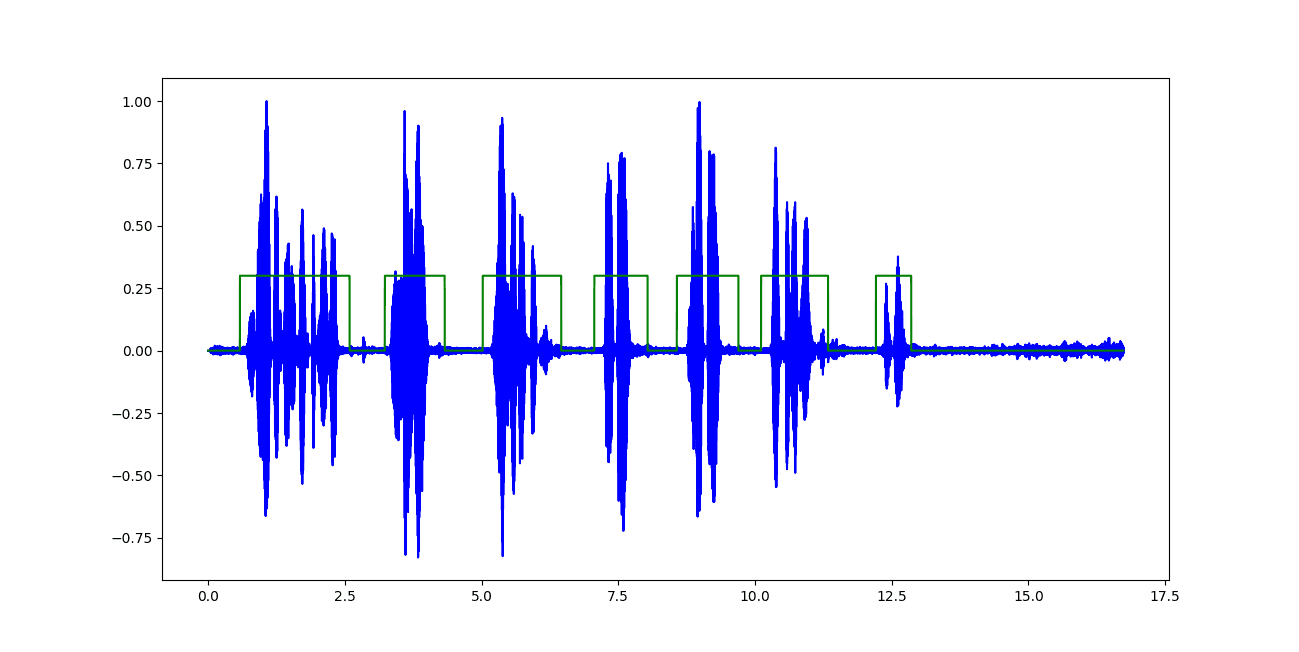
- Speech / non-speech decisions: Drives when to stop listening and reduces accidental cutoffs.
- Endpointing: Helps determine end-of-utterance (EoU) even with pauses and fillers. We can use language or prosody cues to further improve endpointing accuracy.
- Barge-in: Detects user speech during TTS playback to pause/stop output naturally.
Synthetic Voice Generation
An integral part of any voice pipeline is a realistic, responsive and expressive TTS. The choice of a TTS model has implications on the latency and naturalness of the final product. My initial approach was to implement a classic Sequence-to-sequence (Seq2Seq) model from scratch. I quickly realised the time investment needed to build a production ready solution was too high, so I turned to open-source low latency options that could do the job well.
My attempt: Tacotron 2 (from scratch)
My initial research into synthetic voice generation began with Tacotron. The classic encoder-attention-decoder framework made intuitive sense to me, so I attempted to recreate Tacotron 2 using PyTorch. I used the LJSpeech single-speaker dataset for training.
I quickly realized I lacked compute, and that tuning, streaming implementation, and evaluation would demand more time than the project timeline allowed.
To train Tacotron 2 to the extent of intelligible and realistic synthesis, the online community recommendations suggest several hundred thousand training steps. With a batch size of 16 and gradient accumulation of 2, it would have taken me approximately a week of continuous training on a 4060 to fully train the model.
Real-time generation, chunking, and stability are incredibly difficult to implement well. Natural speech inherently depends on upcoming context. Without careful design, you risk wrong prosody or intonation at the expense of latency. Ideally both are important to feel real.
Many objective metrics (mel cepstral distortion, F0 RMSE tests) don't necessarily correlate with natural sounding voices. Instead, Mean Opinion Score (MOS) listening tests are conducted to evaluate naturalness, which obviously is an expensive and time consuming process.
Production ready TTS requires a level of stability in their outputs. Many industry solutions require timeouts (to prevent hanging), clipping and discontinuity prevention, and guardrails on audio frequency and prosody to prevent long pauses or amplitude spikes. These are all non-trivial and development intensive.
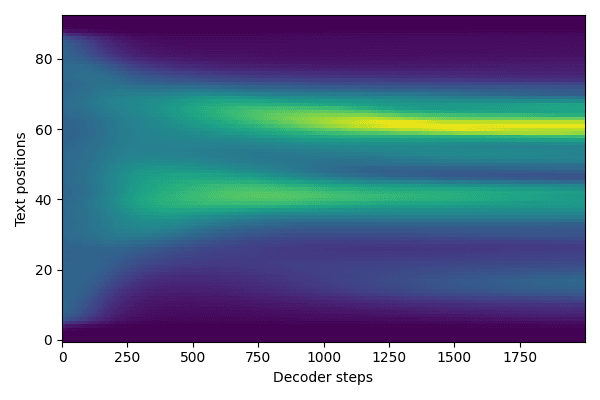
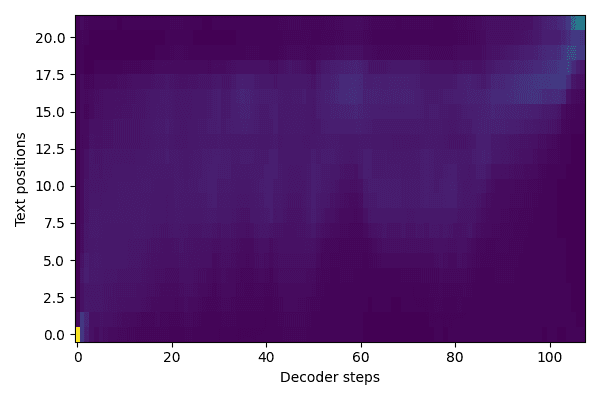
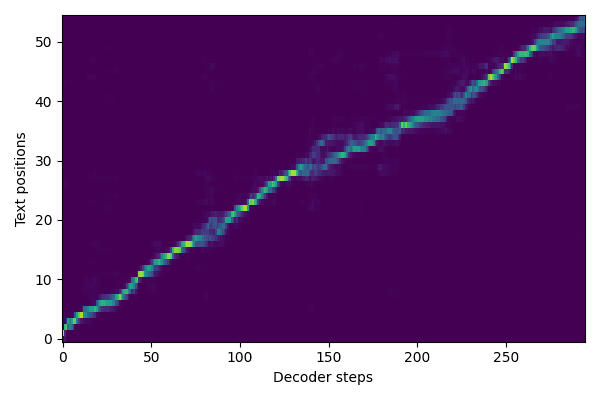
Training artifacts: attention plots and (bad) audio samples
The following are some Attention plots and audio samples from my Tacotron 2 training. You can see I began to align around 24 hours into training. Warning: cover your ears for the audio samples.
Final choice:
VibeVoice Realtime
For Ella, the best TTS model is the one that ships: low latency, stable streaming, and good-enough quality under realistic consumer-hardware constraints. I chose VibeVoice Realtime because of its text streaming support and sub 200ms TTFA (Time to First Audio), as well as its natural and expressive voice quality.
In my testing I had a consistent TTFA of under 200ms, and have had no problems with clipping or audio chuck discontinuity while streaming
The entire VibeVoice family of models can be found on huggingface, and the Realtime model only requires a few Gb of VRAM to run
Instead of getting stuck building a custom TTS stack from scratch, I can use a state-of-the-art open-source model and focus my time on good integration and iteration on the overall product experience.
Audio samples
Here are some sample outputs from the VibeVoice Reatime model. Generation took on average 0.25x the length of the audio playback.